Crafting Technical
Specifications for Custom ChatGPT Implementations
This guide offers step-by-step instructions for crafting technical specifications tailored to implementing ChatGPT solutions with your data. It provides essential insights for seamlessly integrating ChatGPT into your systems, ensuring a customized experience that leverages the power of your unique datasets.

Glossary
NLP (Natural Language Processing): A field of artificial intelligence that focuses on the interaction between computers and humans through natural language. It involves the development of algorithms that allow
computers to process and understand human (natural) languages.
LLM (Large Language Model): A type of artificial intelligence model designed to understand, generate, and interpret human language based on vast amounts of text data. These models can perform a variety of tasks, including answering
questions, writing content, translating languages, and more.
Copilot: An AI-powered language model that can generate results for a wide range of tasks, including generating text, modifying existing text, and answering questions. Copilot has broad knowledge across various domains, including science,
technology, and history, and responds in an encyclopedic and neutral manner.
RAG (Retrieval-Augmented Generation): A method in machine learning where the system retrieves information from a database or corpus to help generate a response.
It's particularly useful in enhancing the accuracy and relevance of responses from models like ChatGPT by providing them with specific, contextually relevant information.
Fine-tuning: The process of adjusting the parameters of a pre-trained model on a specific dataset or for a specific task, to improve its performance or adapt it to different requirements.
Tokenization: The process of converting text into smaller units, such as words, characters, or subwords, which are then used for processing in NLP tasks.
Embeddings: High-dimensional vectors used to represent words, sentences, or entire documents in a continuous vector space. They capture semantic meanings and relationships between linguistic items.
Understanding ChatGPT and Large Language Models (LLMs)
In this section, we delve into the essential characteristics and operational nuances of ChatGPT and Large Language Models (LLMs) to provide stakeholders with a foundational understanding necessary for effectively leveraging these technologies in their projects.
Understanding the operational characteristics, strengths, and limitations of ChatGPT and LLMs is crucial for effectively integrating these technologies into software solutions. By considering the balance between speed and accuracy, token limits, the pricing model, and the potential for hallucination, developers and project managers can better plan and execute projects that leverage the power of LLMs to meet their specific needs.
Model Difference: Speed vs. Accuracy
One of the critical considerations when working with LLMs, including ChatGPT, is the trade-off between speed and accuracy. Different versions of these models are optimized for various tasks, with some prioritizing rapid response times while others focus on delivering the most accurate and contextually relevant information possible.
Speed-Optimized Models: These models are designed to provide responses more quickly. They are typically smaller in size, which means they process inputs and generate outputs at a faster rate. Speed-optimized models are ideal for applications requiring real-time interactions, such as chatbots or interactive tools. However, the trade-off for this increased speed is often a reduction in the depth and accuracy of the responses.
Accuracy-Optimized Models: Larger and more complex models fall into this category. They are capable of understanding context more deeply and producing more accurate, nuanced responses. The trade-off here is that these models require more computational resources, resulting in slower response times. They are suited for tasks where the quality of the output is paramount, such as content creation, detailed analysis, and complex question answering.
Token Limit
LLMs process input and generate output based on tokens, which can be words, parts of words, or punctuation. Each model has a maximum token limit, which affects both the length of the input it can process and the length of the output it can generate.
The token limit is a crucial factor in determining how much information can be processed in a single request. For applications requiring detailed analysis or generating long-form content, understanding the token limit is essential for designing interactions that split the content into manageable chunks.
Pricing
The pricing model for using LLMs like ChatGPT typically depends on several factors, including the number of tokens processed, the computational resources required by the model, and the overall volume of usage.
Most service providers charge based on the amount of text (measured in tokens) processed by the model. This means the cost directly correlates with how frequently the model is used and the complexity of the tasks it performs.
Hallucination
Hallucination refers to instances where LLMs generate incorrect or nonsensical information, often presented with confidence. This phenomenon is a known challenge in AI, stemming from the model's reliance on patterns in data rather than factual accuracy.
Understanding that hallucination can occur is vital for setting realistic expectations for LLM output. It's essential to implement validation mechanisms, such as cross-referencing with trusted data sources or incorporating human review, especially in scenarios where accuracy is critical.
Training vs. Fine-Tuning vs. Retrieval-Augmented Generation (RAG)
To effectively leverage Large Language Models (LLMs) like ChatGPT in various applications, it's crucial to understand the differences and applications of three key concepts: Training, Fine-Tuning, and Retrieval-Augmented Generation (RAG). Each approach has its unique characteristics and use cases in the development and deployment of AI models.
Training
Training refers to the process of building a machine learning model from scratch by exposing it to vast amounts of data. The model learns to understand and generate human-like text by identifying patterns, relationships, and structures within the training dataset.
Characteristics: This process requires substantial computational resources and time, as it involves processing large datasets and adjusting millions (or even billions) of parameters within the model.
Use Cases: Training from scratch is typically performed by organizations with the resources to handle such computational demands, often aiming to create a foundational model that can be adapted to various tasks.
Fine-Tuning
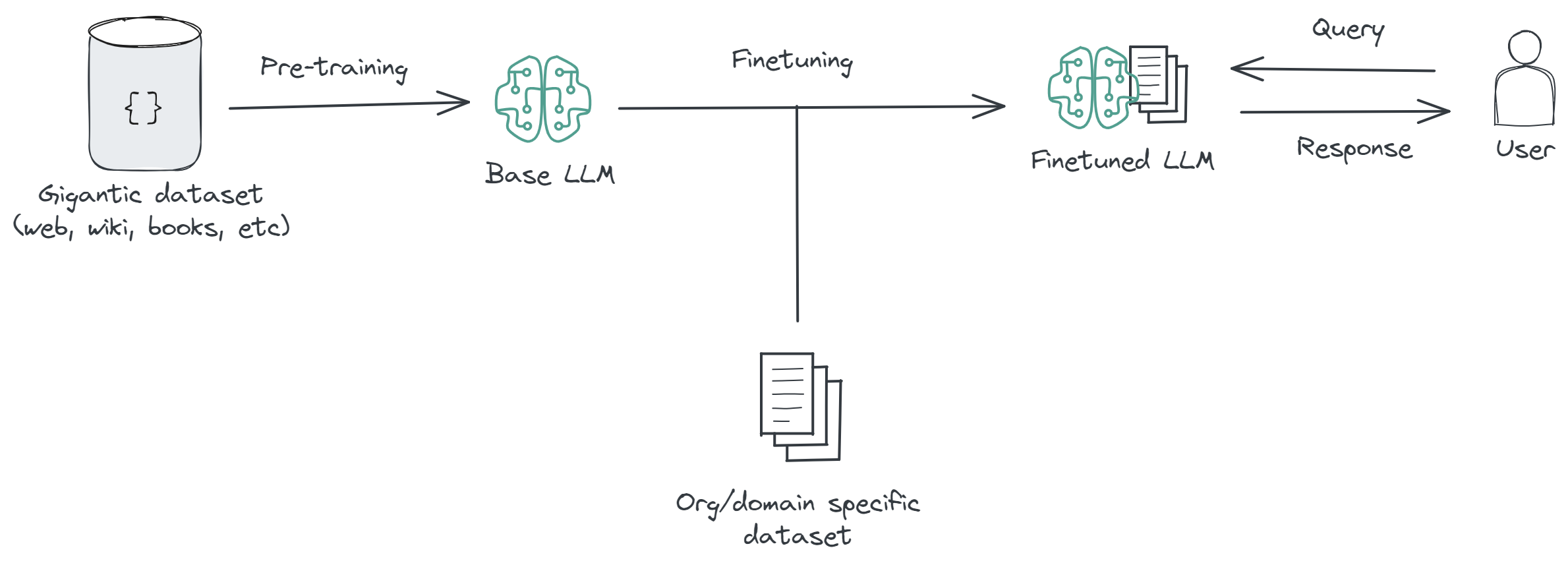
Fine-tuning is a process where a pre-trained model (like ChatGPT) is further trained (or "fine-tuned") on a smaller, specialized dataset. This allows the model to adapt its responses to fit specific domains or applications better.
Characteristics: Fine-tuning requires significantly less computational power and time than training from scratch since the model has already learned general language patterns. The process adjusts the model's parameters to align with the nuances of the new dataset.
Use Cases: Fine-tuning is widely used to create models for specific industries, languages, or unique applications, such as legal document analysis, medical advice, or customer service bots, where the model needs to understand and generate text that aligns with specialized knowledge.
Retrieval-Augmented Generation (RAG)
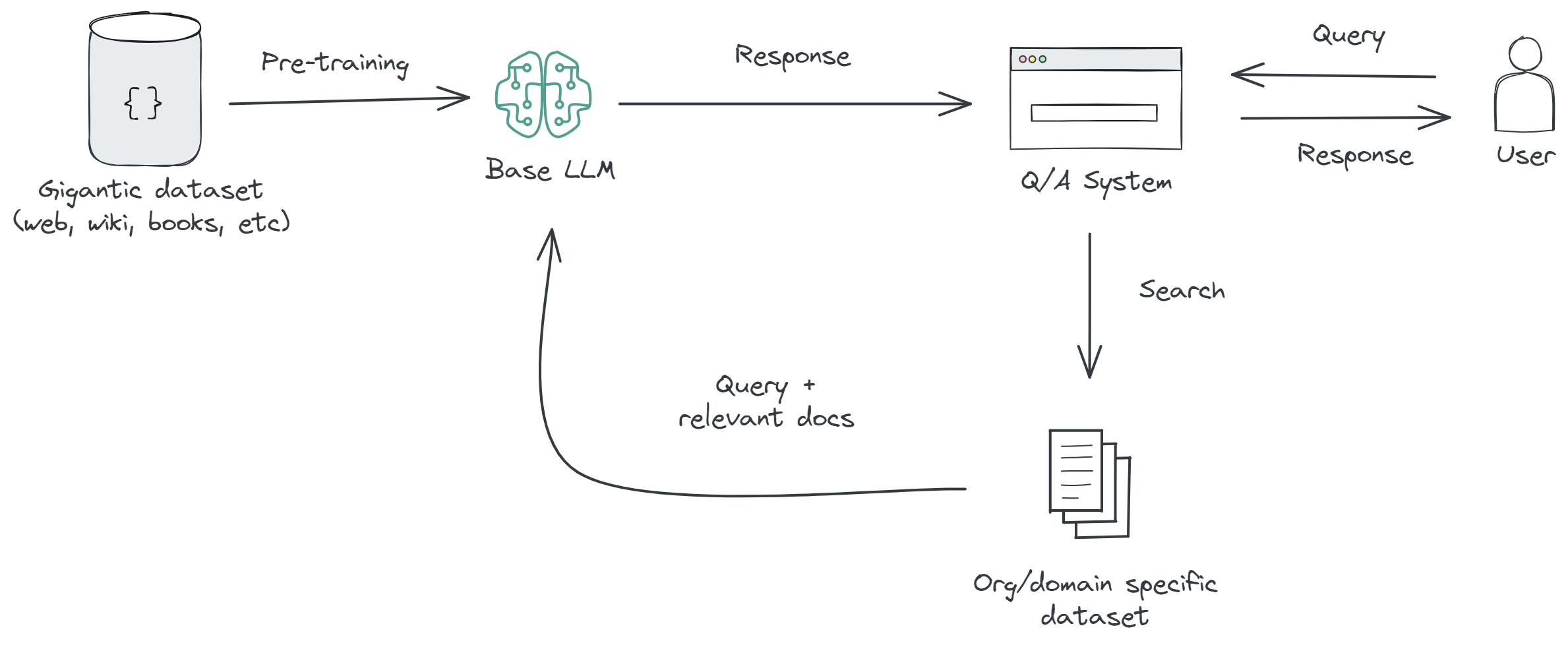
Retrieval-Augmented Generation combines the generative capabilities of models like ChatGPT with a retrieval mechanism that fetches relevant information from a database or knowledge base in real-time. This approach augments the model's responses with up-to-date, accurate information.
Characteristics: RAG enables the model to produce responses that are not only based on the patterns learned during training but also enriched with specific details retrieved from external sources. It involves a dynamic interaction between the generative model and the retrieval system.
Use Cases: RAG is particularly useful for applications requiring high accuracy and up-to-date information, such as news-related queries,
Understanding the distinctions between training, fine-tuning, and Retrieval-Augmented Generation (RAG) is crucial for anyone looking to implement or work with LLMs. Each approach has its advantages and is suited to different types of projects. While training is resource-intensive and generally used for creating foundational models, fine-tuning allows for customization with less resource expenditure. RAG, on the other hand, offers a way to enhance model outputs with external, real-time information, making it ideal for applications where accuracy and timeliness are paramount.
Implementing Retrieval-Augmented Generation on Microsoft Azure
Implementing a Retrieval-Augmented Generation (RAG) system on Microsoft Azure leverages the platform's robust, scalable cloud infrastructure and its suite of AI and machine learning services. By utilizing specific Azure services, organizations can develop sophisticated RAG solutions tailored to their needs. Here’s how to approach the implementation using required and optional Azure services.
The high-level architecture of implementing RAG on Microsoft Azure:
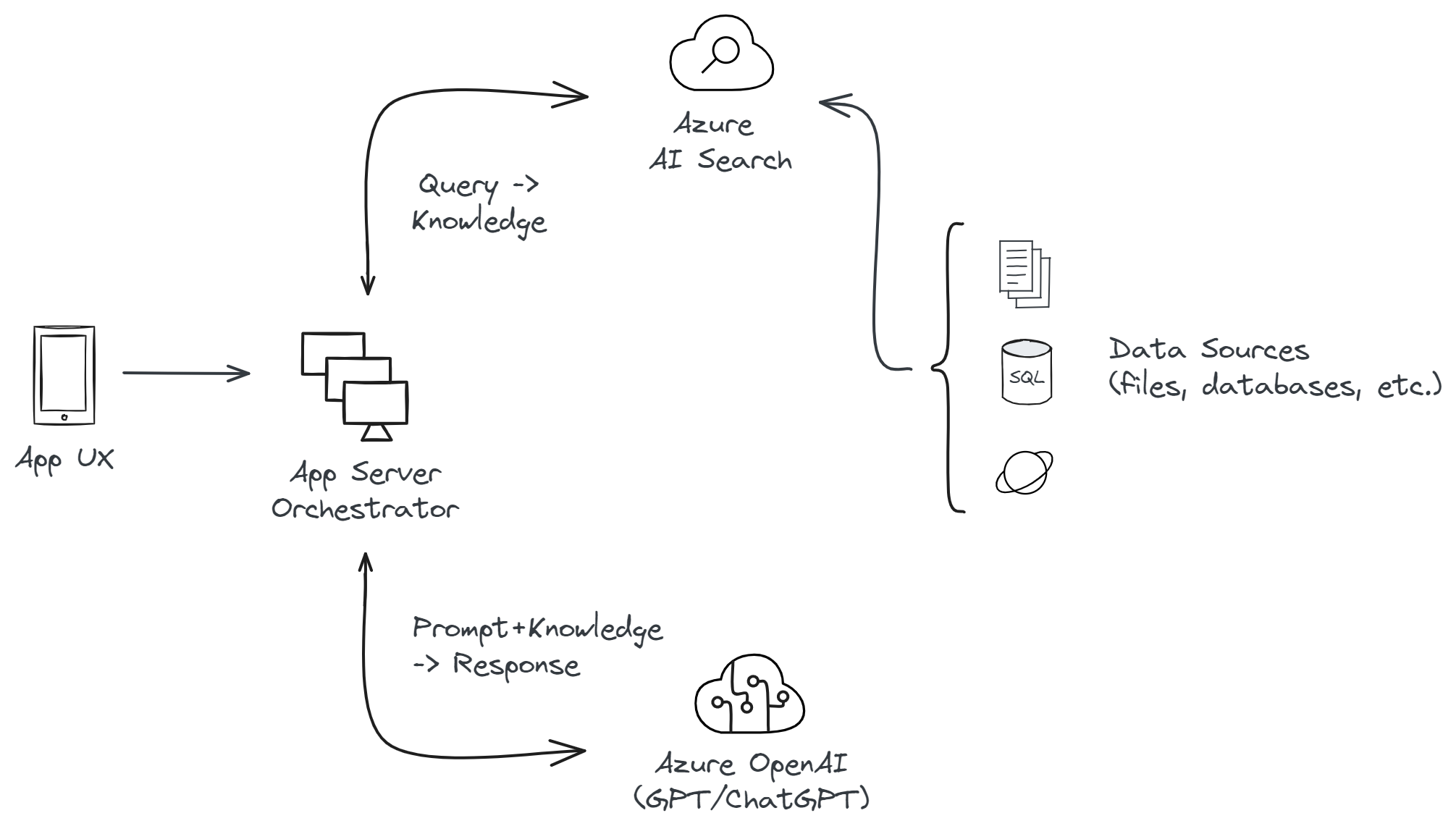
Required services and tools:
Azure OpenAI Service provides access to powerful AI models, including variants of the GPT (Generative Pre-trained Transformer) family, developed by OpenAI.
Azure OpenAI Service allows developers to integrate advanced natural language processing capabilities into their applications, making it ideal for the generative component of a RAG system. With Azure OpenAI Service, you can harness the power of large language models for text generation, summarization, translation, and more, within the security and privacy framework of Azure.
Azure AI Search (formerly known as Azure Cognitive Search) offers AI-powered search capabilities over content in various formats. It can ingest, enrich, and index large amounts of data to make it searchable, supporting a wide range of file types and data sources. It's particularly useful for the retrieval component of RAG, enabling fast and efficient searches across structured and unstructured data. With built-in AI capabilities, such as key phrase extraction and entity recognition, it enhances the search experience by making the data more accessible and actionable.
Semantic Kernel is an open-source SDK that lets you easily build agents that can call your existing code. As a highly extensible SDK, you can use Semantic Kernel with models from OpenAI, Azure OpenAI, Hugging Face, and more! By combining your existing C#, Python, and Java code with these models, you can build agents that answer questions and automate processes.
Optional services based on scenario:
Azure Machine Learning allows developers and data scientists to build, train, and deploy machine learning models at scale.
It supports the entire model lifecycle, from development to deployment, and integrates with other Azure services for a seamless workflow. For RAG implementations, it can be used to fine-tune AI models on specific datasets or to
develop custom models that work alongside Azure OpenAI Service for specialized tasks.
Azure AI Studio (Azure OpenAI Studio successor) is a platform designed for professional software developers to create generative AI applications and custom copilots. It provides built-in security, compliance, and AI services.
With Azure AI Studio, you can work with models from various sources, including OpenAI, Hugging Face, and Meta.
Azure AI Services (e.g., Document Intelligence) offers a range of AI services tailored to specific tasks, such as form recognition, document understanding, and content moderation. Document Intelligence, for example, can extract, analyze, and process information from documents, making it easier to incorporate this data into a RAG system. These services can augment the RAG system by providing additional layers of understanding and interaction with the data, enhancing both retrieval accuracy and the relevance of generated content.
Implementing a Retrieval-Augmented Generation (RAG) system on Microsoft Azure leverages the platform's robust, scalable cloud infrastructure and its suite of AI and machine learning services. By utilizing specific Azure services, organizations can develop sophisticated RAG solutions tailored to their needs. Here’s how to approach the implementation using required and optional Azure services.
Implementing Retrieval-Augmented Generation Using LangChain
Implementing Retrieval-Augmented Generation (RAG) using LangChain involves leveraging its framework for building language applications that combine large language models (LLMs) with external knowledge sources. LangChain is designed to facilitate the creation of AI applications that can access, retrieve, and process information from various databases or knowledge bases in real-time, enhancing the capabilities of LLMs with additional context or specific information not contained within the model itself.
The high-level architecture of implementing RAG using LangChain:
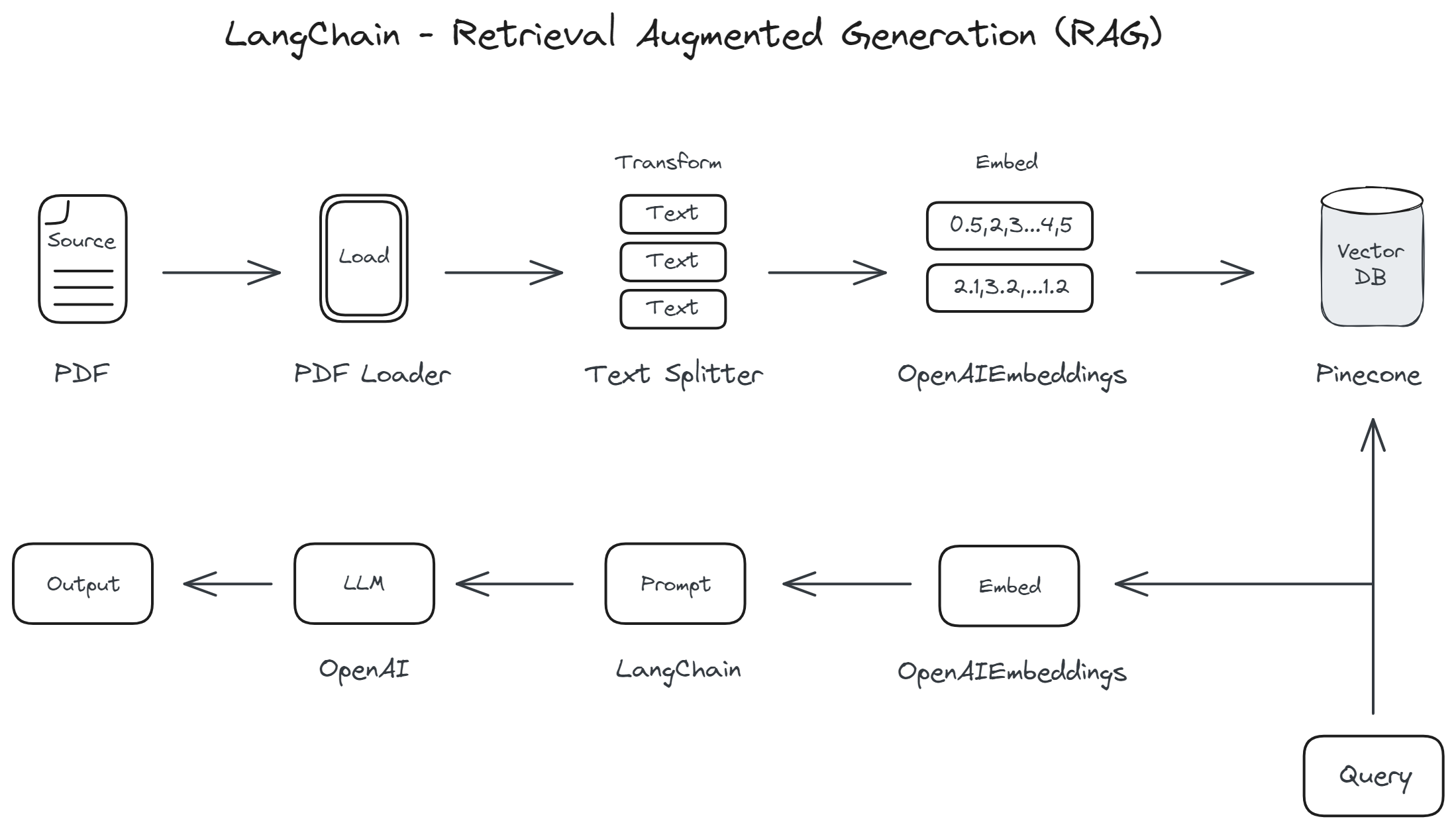
The core concept behind LangChain is to enable a seamless integration between LLMs and external knowledge sources through a modular framework. This allows developers to construct applications where LLMs can dynamically access external data for a wide range of tasks, including but not limited to information retrieval, question answering, and content generation. Here’s how LangChain typically works in the context of RAG:
Query Processing: The system first processes the user's query or prompt to understand the request and determine the need for external data.
Retrieval: Based on the processed query, LangChain interacts with one or more external knowledge sources to retrieve relevant information. This step is facilitated by querying vector databases that store information in a way that's efficiently searchable by semantic content, rather than traditional keyword matching.
Integration: The retrieved information is then integrated with the LLM's capabilities, either by providing the model with context before generating a response or by incorporating the external data into the model's output directly.
Response Generation: Finally, the LLM generates a response based on both its internal knowledge and the information retrieved from external sources, resulting in an output that is more informed, accurate, and contextually relevant.
For the retrieval component of LangChain, vector databases play a crucial role in efficiently storing and accessing large amounts of data based on semantic similarity. These databases allow for the quick retrieval of information that is contextually relevant to the query, even if the exact keywords are not present. Some popular vector databases that can be integrated with LangChain include:
Elasticsearch with the Vector Search Plugin: Elasticsearch is a highly scalable search engine that can be enhanced with plugins to support vector search capabilities. It allows for the storage and retrieval of high-dimensional vector data alongside traditional search functionalities.
Faiss (Facebook AI Similarity Search): Developed by Facebook AI Research, Faiss is a library for efficient similarity search and clustering of dense vectors. It's particularly well-suited for applications requiring fast searches in large datasets.
Pinecone: A managed vector database service designed specifically for machine learning applications. Pinecone makes it easy to build and scale vector search applications, offering high performance and simplicity for developers.
Weaviate: An open-source vector search engine that enables scalable, real-time vector search. Weaviate comes with built-in support for semantic search, making it a good choice for applications leveraging LangChain.
Milvus: An open-source vector database designed for AI and similarity search applications. Milvus supports scalable, distributed vector storage and search, making it suitable for enterprise-level applications.
Each of these vector databases offers unique features and capabilities, allowing developers to choose the most appropriate solution based on their specific requirements, such as dataset size, search performance needs, and scalability considerations.
Implementing RAG with LangChain involves integrating these vector databases to provide the LLM with access to a rich external knowledge base, enhancing the quality and relevance of the generated responses.
Preparing Data for Retrieval-Augmented Generation (RAG)
For effective utilization of Retrieval-Augmented Generation (RAG), understanding and preparing the data types involved is crucial. Here's a breakdown of how to approach the preparation of various data types for RAG systems:
Structured Data
Definition: Structured data refers to any data that adheres to a specific format, allowing it to be easily searched and processed by algorithms. Examples include databases and spreadsheets where information is organized into rows and columns.
Preparation: Access to structured data is often best facilitated through APIs, which allow for dynamic querying and retrieval of data in a structured manner. Ensure APIs provide clean, well-documented access to the data.
Unstructured Data
Definition: Unstructured data is information that doesn't have a pre-defined format, making it more challenging to process automatically. Common forms include text documents, emails, and multimedia content.
Preparation: For RAG systems, unstructured data should be converted into machine-readable formats. Prioritize text-based formats like TXT or Markdown for ease of processing. PDFs and Word documents are also common but may require additional parsing to extract the text accurately.
Specific Data Types
Definition: This category includes specialized formats such as Excel spreadsheets, images, or drawings that may contain valuable information for retrieval but are not inherently text-based.
Preparation: Convert these data types into a format that can be processed by the RAG system. For example, extract tables from Excel files as CSV, and use OCR (Optical Character Recognition) for text in images or drawings. Adjustments should align with business requirements and the specific nature of the data.
Chunking
Definition: Chunking involves breaking down data into smaller, manageable pieces that can be independently processed and retrieved.
Preparation: Ensure that each chunk is complete and self-contained to avoid dependencies on other data segments. This approach enhances the efficiency and accuracy of the retrieval process.
Change Frequency
Definition: This refers to how often the data is updated or changed. The frequency of changes can impact both the retrieval system's design and its operational costs.
Preparation: Define a schedule for data updates that balances currency with cost. Implement mechanisms for efficiently updating the dataset to reflect changes without requiring a complete re-indexing of the data.
Size of Data and Deltas
Definition: The total size of the data and the size of changes (deltas) introduced during updates are important considerations for storage and processing.
Preparation: Assess the initial data size and estimate the volume of expected updates. This assessment will guide the selection of storage solutions and update mechanisms that can handle the data volume efficiently.
Dependencies
Definition: Dependencies in data refer to instances where understanding one piece of information requires access to another, potentially unrelated piece.
Preparation: RAG systems work best with data that is as independent as possible. Review the dataset to identify and minimize cross-references. Simplifying the structure of the data enhances the model's ability to retrieve and utilize information accurately.
Questions To Be Answered
- What types of data (structured, unstructured, specific formats) will be integrated into the RAG system, and in what formats are they currently stored?
- Can you provide detailed documentation for APIs that access structured data, including any access restrictions or authentication requirements?
- For unstructured data, are there specific formats (e.g., TXT, PDF, Word) predominantly used, and are there requirements for converting non-textual information (e.g., images) into machine-readable text?
- How is the data currently organized, and can it be segmented into independent, self-contained chunks suitable for efficient retrieval?
- What is the frequency of data updates, and are these updates incremental or do they require a complete dataset refresh?
- What is the total size of the dataset and the expected size of incremental updates (deltas)?
- Does your data contain any dependencies or cross-references that could affect retrieval, and how can these be minimized or structured for independence?
Queries Orchestration
Implementing effective queries orchestration within a Retrieval-Augmented Generation (RAG) system requires a comprehensive approach to manage and direct queries to the most appropriate source of information, whether it be a general LLM knowledge base, an API, private unstructured data, or human interaction during live sessions. The orchestration layer must be capable of understanding the nature of the user's query to route it correctly and provide the most relevant and accurate response. Below are the modes and strategies for handling various types of queries:
Information Sources
General LLM Knowledge Base: For queries that involve general knowledge, trivia, or information that doesn't require up-to-the-minute accuracy. The LLM can generate responses based on its extensive training data.
API: For queries that require real-time data or access to structured data not available in the LLM's training set. Examples include weather forecasts, stock prices, or integrating with enterprise systems for specific operations like booking or scheduling.
Private Unstructured Data: For queries that need information from the organization's own repositories, such as internal documents, reports, or databases. This mode is essential for questions that require personalized or sensitive information.
Human During Live Sessions: For queries that require human judgment, are too complex for the AI, or when the user explicitly requests to speak with a human. This mode is crucial for high-stakes interactions or when personal touch is needed.
Types of Queries and Orchestration Strategies
Small Talk (e.g., "Hello," "How do you do?"): These queries are usually handled directly by the general LLM knowledge base, as they do not require specialized knowledge or access to external data sources.
General Questions (FAQ): Frequently asked questions can be managed by the LLM, possibly augmented with information from an API or private unstructured data if the FAQs are stored in such sources.
Follow-Up Questions (e.g., "What are my next steps?"): These queries may require context from previous interactions. The orchestration layer must maintain session context to provide coherent and relevant responses, potentially utilizing all information sources based on the context.
Queries Requiring Personal Data (e.g., "Give me my salary report for the last month"): Such queries should be routed to access private unstructured data or APIs interfacing with secure, authorized systems that contain user-specific information.
Handoff to Live Agent Requests (e.g., "I want to talk with a human"): The system must recognize this request type and seamlessly transition the session to a live agent, ensuring the agent is briefed on the context of the interaction.
Self-Service Scenario Calls (e.g., "You want to register, please follow these steps"): These can often be handled by the LLM providing guided steps stored in its knowledge base, augmented with API calls if the process requires interacting with external systems (e.g., registration systems).
Work To Be Done
- Information Sources, Types of Queries, and Workflow Definition: Clients should meticulously define schemas and workflows for each type of communication, identifying the sources of information relevant to each and the logic for routing queries. This includes mapping out user intents, expected actions, and response generation mechanisms.
- Validation Dataset: Clients should prepare a list of questions and expected responses. It can be a simple Excel/csv file with two columns: Input, Expected Response.
- Human Handoff Protocols: Establish clear protocols for transitioning to live human agents, including transferring session context and ensuring a smooth handover to maintain user satisfaction.
Updating the Knowledge Base
For a Retrieval-Augmented Generation (RAG) system to remain effective and relevant, the knowledge base (KB) it relies on must be kept up to date. This involves not just the addition of new data but also modifications to existing data and potentially changes to the knowledge base's structure. Clients must carefully define their requirements and scenarios for updating their KB to ensure the RAG system maintains high accuracy and relevance. Below are considerations and questions to guide this process:
How often do you anticipate the knowledge base will need updates? This could range from real-time updates for dynamic data to less frequent updates for more stable knowledge domains.
What triggers an update? Determine whether updates are scheduled (e.g., daily, weekly) or event-driven (e.g., after significant events that introduce new relevant information).
What is the expected size of each update batch? Understanding the volume of data added or modified with each update helps plan for the computational resources needed.
Will updates include new types of information or data sources? This affects whether the RAG system needs to accommodate new formats or structures.
How will updates impact the integrity and structure of the knowledge base? It's crucial to maintain consistency and avoid introducing errors or duplications.
Are there plans to evolve the knowledge base structure over time? If the knowledge base structure is expected to change (e.g., adding new fields, changing data relationships), the RAG system may need to adapt to these changes.
What balance of automated versus manual updates is anticipated? While automated updates can save time and resources, manual updates may be necessary for quality control or to handle complex changes.
What processes will be in place to validate and test the knowledge base after updates? Ensuring the accuracy and integrity of the KB after updates is essential for the reliability of the RAG system.
What are the rollback procedures in case an update introduces errors? Having a plan to revert changes is crucial for maintaining system stability.
Will users be notified of updates, and if so, how? Depending on the application, it may be necessary to inform users about updates, especially if these significantly impact the functionality or information available.
Unrealistic Expectations to Avoid
When drafting requirements for a ChatGPT or any AI-based solution, it's important to set realistic and technically feasible expectations. Certain demands can set projects up for failure or misalignment between client expectations and what the technology can deliver. Here are some points that should not be included in the requirements due to their unrealistic or unfeasible nature:
Model Should Not Hallucinate: While it's crucial to strive for accuracy and minimize misinformation, it's unrealistic to demand that a model never produces hallucinated (inaccurate or fabricated) information. Developers can implement strategies to reduce hallucination, such as fine-tuning and implementing validation checks, but eliminating it entirely is not feasible due to current technological limitations.
Chatbot/Solution Should Be Trained on Your Data: ChatGPT and similar models are pre-trained on diverse datasets and can be fine-tuned to adapt to specific styles, tones, or domain-specific knowledge. However, training a model from scratch on proprietary data typically requires alternative approaches, such as using open-source models like LLaMA 2 from Meta, and significant computational resources.
Chatbot/Solution Must Learn Continuously: AI models like ChatGPT operate within the constraints of their training and do not learn or adapt from interactions post-deployment in real-time. While models can be periodically updated or fine-tuned with new data, they do not inherently "learn" from each interaction in the way humans do.
Chatbot/Solution Should Support Any Type of Data and Future Scenarios Without Additional Development: While flexibility and scalability are desirable, it's unrealistic to expect a solution to automatically adapt to any type of data or support new scenarios without further development and testing. Extending support for new data types or scenarios may require model retraining, software updates, and thorough validation to ensure performance and accuracy are maintained.
Chatbot/Solution Should Respond to All Types of Requests, Independently: Giving a chatbot or AI solution full autonomy to respond to all types of requests without human oversight is risky and not recommended. AI systems should operate within a controlled environment with clear boundaries and oversight mechanisms to prevent the dissemination of incorrect information, ensure compliance with ethical guidelines, and align with legal requirements.
Non-Technical Requirements
When deploying AI solutions like a ChatGPT-based system on platforms such as Microsoft Azure, it's crucial to address not just the technical aspects but also the non-technical requirements.
These requirements ensure the solution aligns with best practices in data security, legal compliance, ethical considerations, and more. Here’s an expanded list of non-technical requirements to consider:
Data Security and Governance
- Data Protection: Implement measures to secure data at rest and in transit, using encryption, secure access controls, and regular security audits.
- Privacy Compliance: Ensure the system complies with privacy laws and regulations relevant to the jurisdictions in which it operates (e.g., GDPR, CCPA).
- Data Retention and Deletion Policies: Define clear policies for data retention and deletion to comply with legal requirements and privacy standards.
Legal
- Compliance with Regulations: Adhere to all relevant legal and regulatory requirements, including those related to data protection, copyright law, and industry-specific regulations.
- Intellectual Property Rights: Ensure that the use of data, algorithms, and any third-party components does not infringe on intellectual property rights.
- Liability and Risk Management: Identify potential liabilities associated with the AI solution and implement strategies to manage these risks.
Microsoft Responsible AI Principles Alignment
- Fairness: Ensure the AI system is designed to treat all users fairly, mitigating biases in AI models and datasets.
- Reliability & Safety: Implement mechanisms to ensure the AI system operates reliably and safely under a wide range of conditions.
- Privacy & Security: Prioritize user privacy and data security throughout the system's lifecycle.
- Inclusiveness: Design the AI solution to be accessible and usable by people with a wide range of abilities, backgrounds, and languages.
- Transparency: Maintain transparency in AI operations, allowing users to understand how and why decisions are made.
- Accountability: Ensure mechanisms are in place for accountability in AI systems' decisions and operations.
Response Quality Monitoring
For any AI-driven solution, especially those involving conversational interfaces or decision-support systems, monitoring the quality of responses is critical to ensure the reliability and effectiveness of the service.
Implementing a robust mechanism for identifying, storing, and evaluating poor responses allows for continuous improvement and maintenance of high-quality user interactions. Below are key components and strategies for monitoring poor
responses within an AI solution.
Response Logging and Storage
- Comprehensive Logging: The solution must automatically log all user requests and the system's responses. This data should include timestamps, user identifiers (where applicable and compliant with privacy laws), and any relevant context that might affect the response quality.
- Secure Storage: Stored data should be encrypted and managed in accordance with data protection regulations (e.g., GDPR, CCPA) to ensure user privacy and data security.
Quality Evaluation
- Automated Scoring: Implement automated scoring mechanisms where possible, using natural language processing (NLP) techniques to evaluate the relevance and accuracy of responses based on predefined criteria.
- User Feedback: Incorporate user feedback mechanisms, allowing users to rate the quality of responses. This direct feedback can be invaluable in identifying responses that did not meet user expectations.
- Manual Review: Establish a routine process for manual review of responses, especially those flagged by automated systems or users as inadequate. This review process can help understand nuanced issues that automated systems might miss.
Monitoring and Alerting
- Thresholds for Alerts: Define specific thresholds for what constitutes a "poor response," based on automated scoring, user feedback, or a combination of both. When responses fall below these thresholds, they should trigger alerts.
- Alerting Mechanisms: Implement an alerting mechanism that notifies responsible personnel or teams when poor responses are detected. Alerts should include details about the interaction to facilitate investigation.
Investigation and Improvement
- Root Cause Analysis: For flagged responses, conduct a root cause analysis to determine why the response was inadequate. This could involve issues with the AI model, data inaccuracies, or unforeseen user queries.
- Continuous Learning Loop: Use insights from the investigation to improve the AI model and its responses. This might involve retraining the model, updating the knowledge base, or refining response generation algorithms.
- Documentation and Reporting: Document instances of poor responses and the measures taken to address them. Regular reporting to stakeholders can help track improvements over time and identify areas for further development.
Ethical and Privacy Considerations
- Anonymization: When storing and reviewing user interactions, ensure that personal information is anonymized to protect user privacy.
- Transparency: Be transparent with users about how their feedback is used to improve the system and ensure they are aware of their contribution to enhancing service quality.
Software Development Requirements Example
The goal of this project, called "ChatGPT-RAG Solution," is to develop a ChatGPT-based AI solution that leverages Retrieval-Augmented Generation (RAG) to deliver accurate and relevant responses to user queries.
The system will process structured, unstructured, and specific data types from sources such as APIs, databases, and text documents.
Technical Requirements:
- Approach Selection: The system must use RAG.
- Model Selection: The system must use a ChatGPT model optimized for accuracy.
- Data Sources: The system must process unstructured PDF/Word/text files that are stored in Microsoft SharePoint. Additional APIs should be used for user-specific queries. Approximate size of data is 1 GB.
- Query Orchestration: The system must have a robust query orchestration layer to handle different types of queries, routing them to the appropriate information source, including APIs and private unstructured data. The general LLM knowledge base should not be used. Handoff to live operator is not applicable.
- Response Style and Tone of Voice: Answers should be laconic in professional style and contain references to origin documents (or we need to use defined Personas).
- Knowledge Base Updates: The knowledge base must be kept up to date with regular updates (one per week) by replacing old files with new versions. New files can be added approximately once per month.
- Architecture and Hosting: The system should be implemented on a cloud platform, such as Microsoft Azure, leveraging its AI and machine learning services, including Azure OpenAI Service and Azure AI Search.
- Quality Monitoring: The system should store all conversation (with anonymization) and provide a feedback mechanism. Alerts should be sent to the IT department if a poor quality response is reported.
Materials Provided:
- Workflow Schemas.
- API description.
- Query Examples with Expected Responses.
- Example PDF/Word files to be used.
Looking for more details? Check out our Retrieval-Augmented Generation development services,
Enabling Quick Access to Corporate Knowledge For Minimizing Support Specialist Dependency case study, or contact us.