Retrieval-Augmented Generation Application Development
Unlock actionable insights by converting organizational knowledge into AI-driven solutions that enable faster and more reliable information retrieval.
What is Retrieval-Augmented Generation?
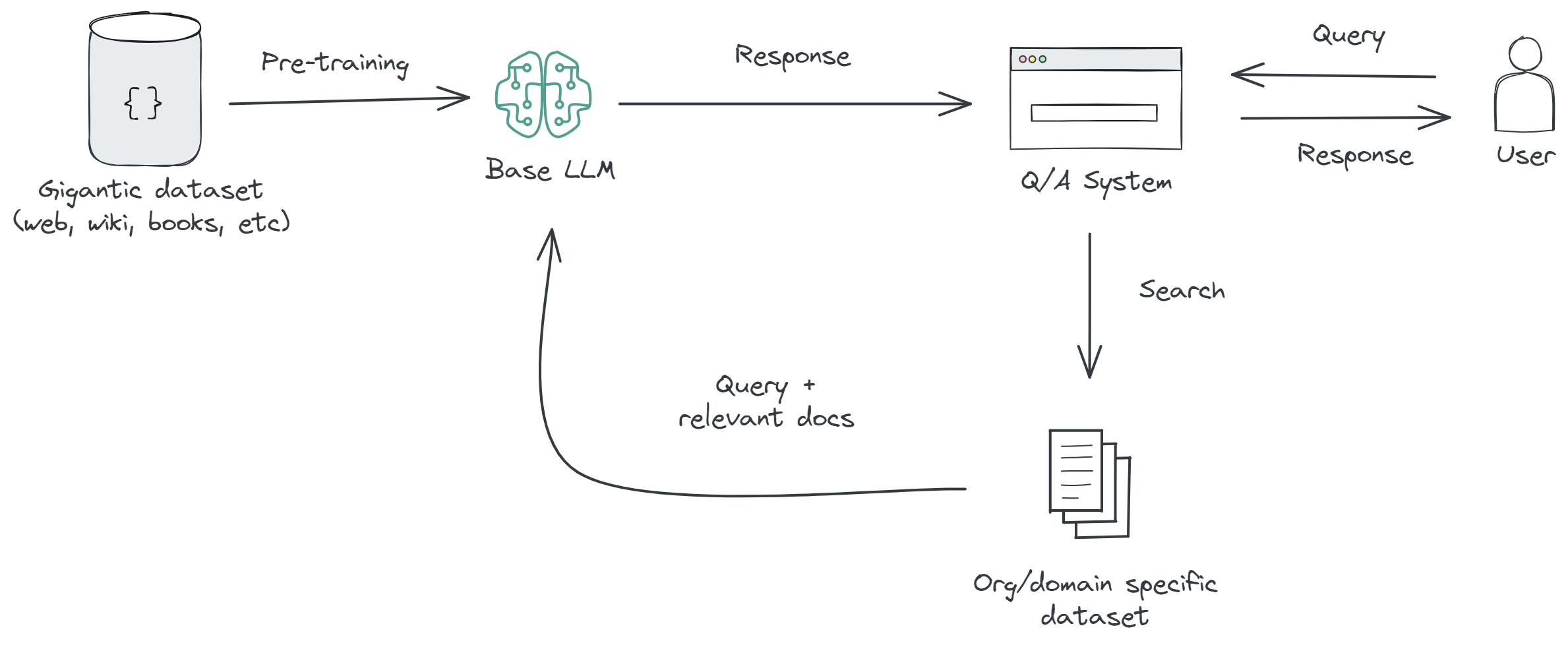
Retrieval-Augmented Generation (RAG) is a technique used in natural language processing, consisting of three key components:
- Retrieval. The system retrieves relevant documents or information from a large dataset. This step is crucial for finding the most pertinent information related to the query or context. It's like searching through a vast library to find the books or pages that have the answers.
- Augmentation. The retrieved information is processed, filtered, and sometimes re-ranked to ensure only the most relevant data is used. This step enhances the quality and reliability of the retrieved content before passing it to the generation model.
- Generation. After retrieval and augmentation, a large language model (like GPT or Claude) synthesizes the refined information into a coherent, contextually appropriate response or content.
This technique is particularly useful for applications where the AI needs to provide detailed, accurate information that might not be contained in its initial training data. It's a way of expanding the AI's knowledge base in real-time to include more detailed or recent information.
Building Knowledge Base
Each of these data sources can significantly enrich the knowledge base of a RAG system, enabling it to deliver more accurate, contextually relevant, and useful responses tailored to the specific needs of the user or organization.
A knowledge base for RAG typically includes documents in common formats such as PDF, Microsoft Word, and Markdown,
including reports, manuals, policies, and internal guidelines, as well as content stored in enterprise knowledge
platforms like SharePoint, Confluence, or Zendesk, and information published on internal portals or
intranet sites. These sources usually form the core textual foundation for retrieval and grounding.
In addition, a knowledge base may include data from private systems such as CRM platforms, internal databases,
and communication tools. This can involve structured data like customer records and transactions, as well as
unstructured data such as support tickets, emails, and internal messages. Regulatory documentation, financial
reports, and technical or research materials are incorporated when required by the use case.
If you want to learn more, check out Crafting Technical Specifications for Custom ChatGPT Implementations blog article.
How We Work?
We use two approaches to support different client needs and levels of project complexity.
Code approach. For complex systems demanding high-quality solutions, we utilize a code-based approach
built on top of Azure services.
This method allows for greater customization, scalability, and precision, making it ideal for clients with specific,
intricate requirements.
The Azure platform provides robust infrastructure and security, ensuring reliable and secure operations.
Low-code approach. For clients seeking a quicker deployment and ease of use,
we offer a low/no code approach. This method is integrated with platforms like Microsoft Copilot Studio or n8n.
While this approach is easier to start and more user-friendly, it may offer slightly less customization and depth compared to the code-based approach.
It's perfect for clients who need a more straightforward, cost-effective solution.
We pay special attention to model selection, as it significantly influences the overall cost and efficiency of the project.
We make informed decisions based on detailed analysis, and for further insights, we refer our clients to
Calculating OpenAI and Azure OpenAI Service Model Usage Costs
blog post that elaborates on calculating model consumption.
This ensures transparency and helps in selecting the most cost-effective model for your needs.
To enhance the capabilities of Large Language Models, we incorporate advanced tools like LangChain and Semantic Kernel.
For a comprehensive overview of our technological capabilities, we invite you to visit our Technologies page.
By combining these methodologies and tools, we ensure that our solutions are not only tailored to our clients' specific needs but also remain at the forefront of technological innovation and efficiency.
Ready to get started?
Let's discuss how AI can transform your business today